The ingredients of a reproducible machine learning model
Chloe Mawer, PhD
Principal Data Scientist, Lineage Logistics
Adjunct Lecturer, Masters of Science in Analytics, Northwestern University
Irreproducibility in the wild


How to write unmaintainable code by Roedy Green

Why is this so hard?
Randomness is everywhere
- Sampling of data for training
- Train/test split
- Model initialization
- Sampling of data within algorithm
- Order of exposure of the model in training to the data
- Sampling of data for evaluation and cross validation
- And more!
The path is long
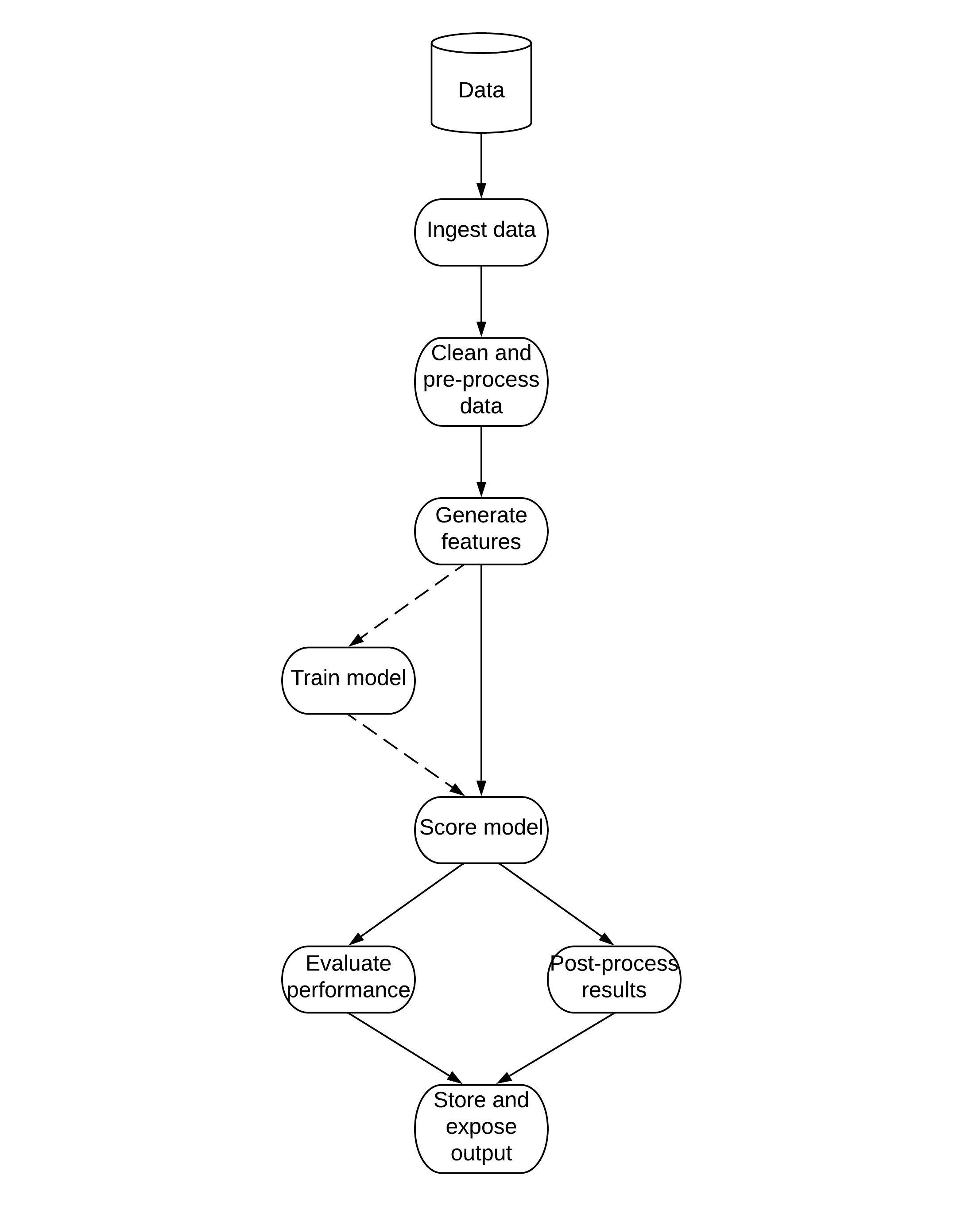
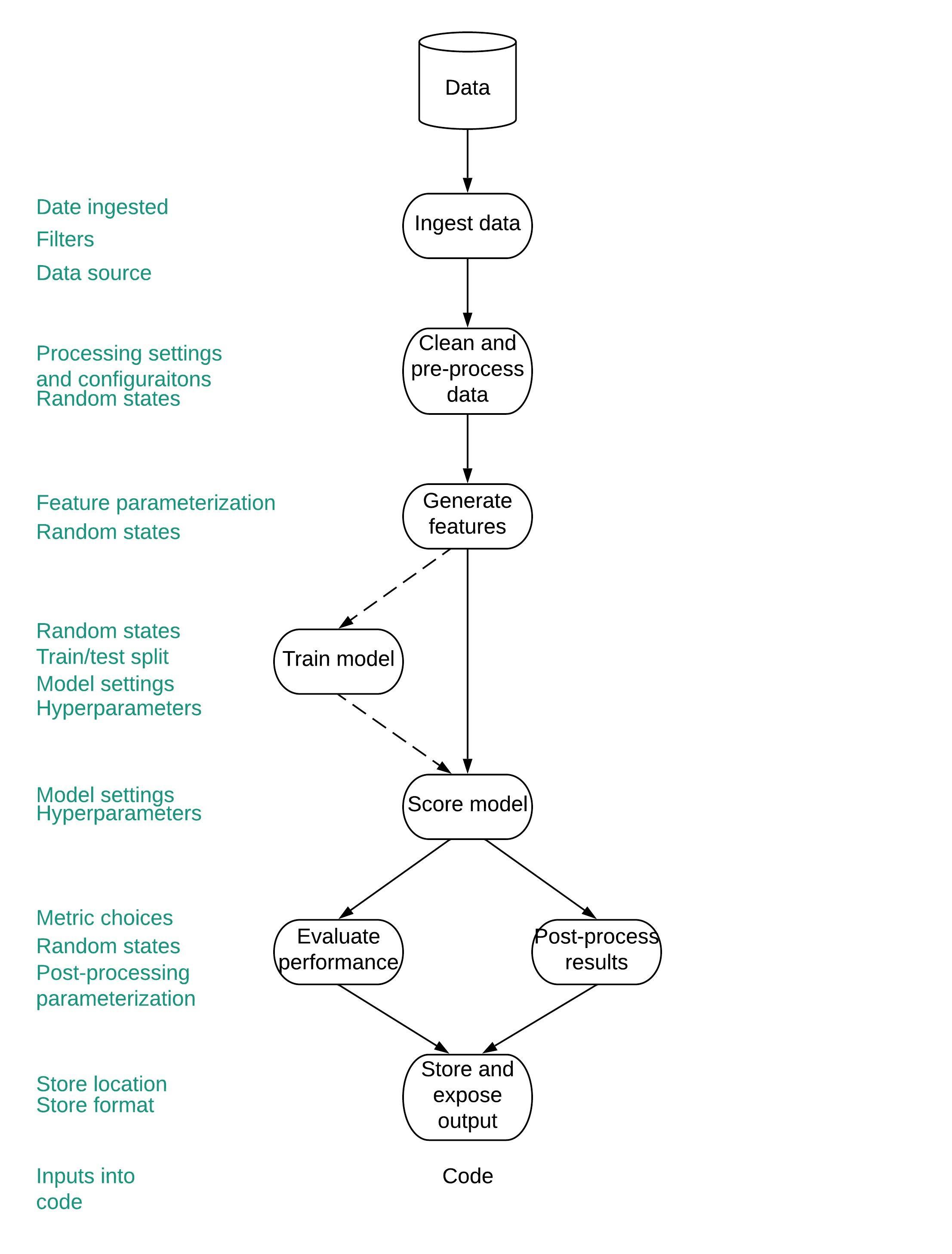
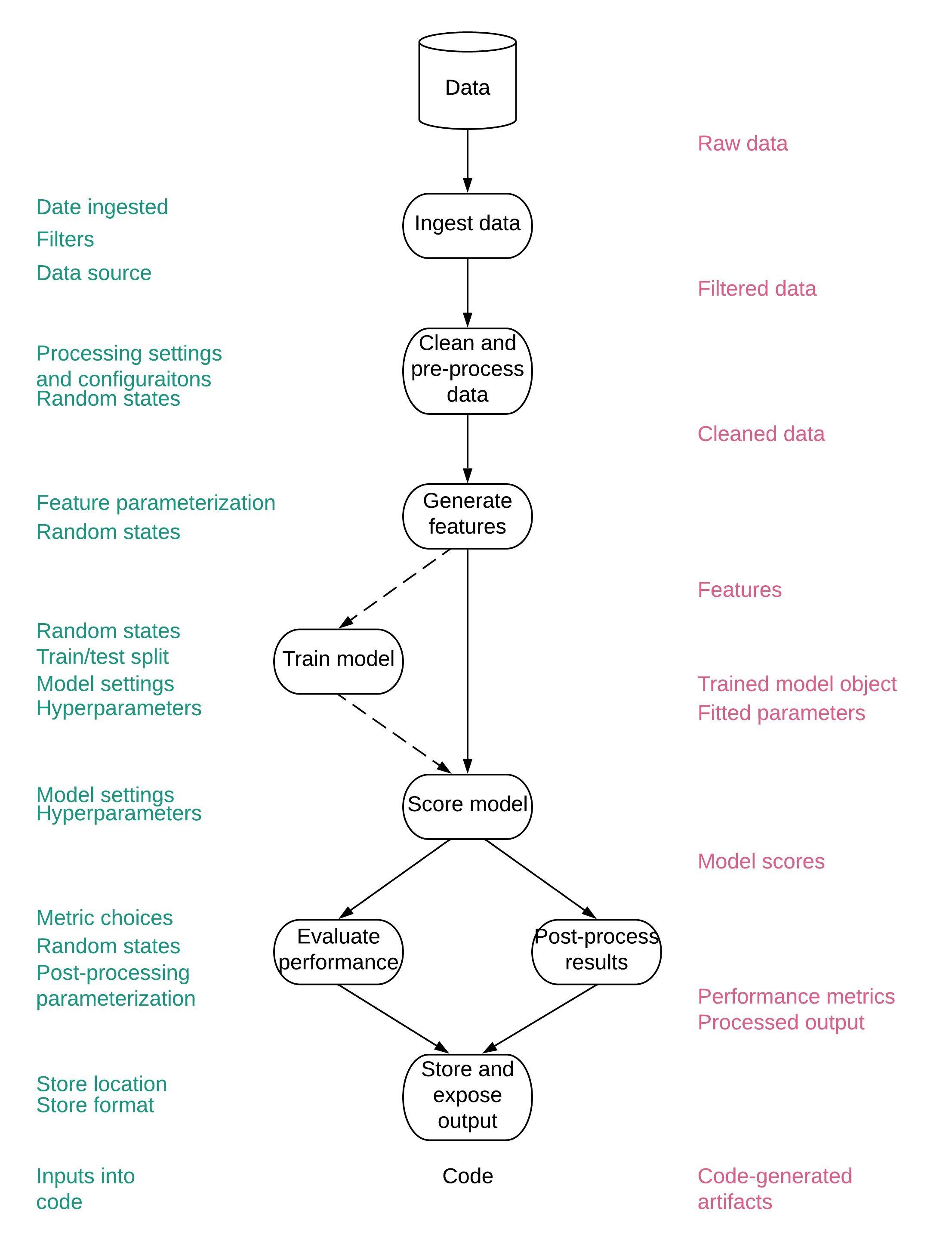
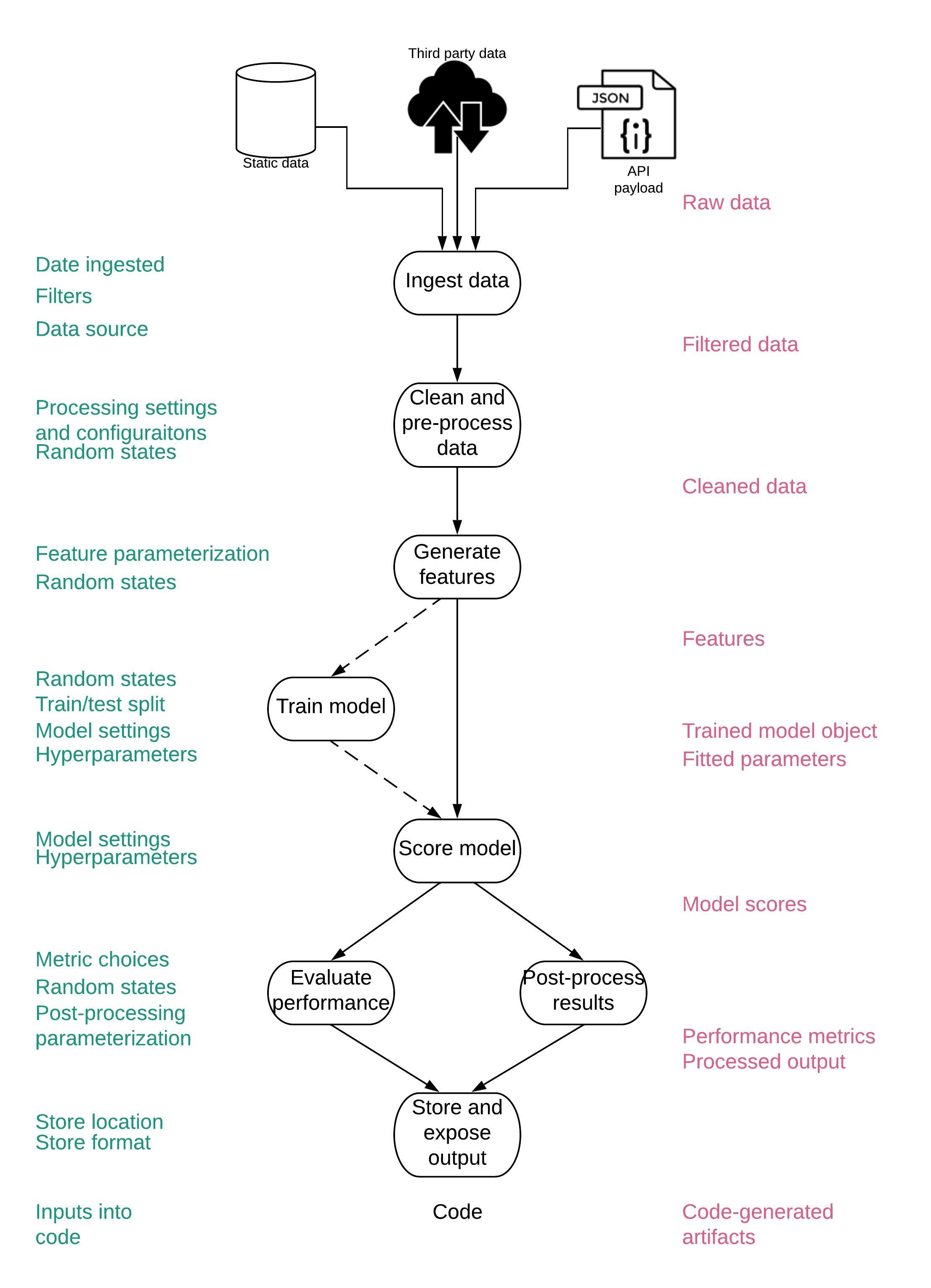
Ingredients of a reproducible model
Determinism
Find every random state and parameterize it
Versioning of everything
Versioning code is not enough
├── src <- Source data for the model
│ ├── ingest_data.py <- Script for ingesting data from different sources
│ ├── generate_features.py <- Script for cleaning and transforming data for use in training and scoring.
│ ├── train_model.py <- Script for training machine learning model(s)
│ ├── score_model.py <- Script for scoring new predictions using a trained model.
│ ├── postprocess.py <- Script for postprocessing predictions and model results
│ ├── evaluate_model.py <- Script for evaluating model performance
│
├── run.py <- Simplifies the execution of one or more of the src scripts
├── requirements.txt <- Python package dependencies Parameters and settings
model:
name: example-model
author: Chloe Mawer
version: AA1
description: Predicts a random result given some arbitrary data inputs as an example of this config file
tags:
- classifier
- housing
dependencies: requirements.txt
load_data:
how: csv
csv:
path: data/sample/boston_house_prices.csv
usecols: [CRIM, ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO, B, LSTAT]
generate_features:
make_categorical:
columns: RAD
RAD:
categories: [1, 2, 3, 5, 4, 8, 6, 7, 24]
one_hot_encode: True
bin_values:
columns: CRIM
quartiles: 2
save_dataset: test/test/boston_house_prices_processed.csv
train_model:
method: xgboost
choose_features:
features_to_use: [ZN, INDUS, CHAS, NOX, RM, AGE, DIS, RAD, TAX, PTRATIO]
get_target:
target: CRIM
split_data:
train_size: 0.5
test_size: 0.25
validate_size: 0.25
random_state: 24
save_split_prefix: test/test/example-boston
params:
max_depth: 100
learning_rate: 50
random_state: 1019
fit:
eval_metric: auc
verbose: True
save_tmo: models/example-boston-crime-prediction.pkl
evaluate_model:
metrics: [auc, accuracy, logloss]config.yml
Data
- At minimum, version an explicit query and include in configuration filters used.
- Source data can change so even this is not sufficient in many cases.
- Ideally, you can version the entire training dataset through tools like
gitlfs,S3or your own tables in HDFS or the database of your choosing.
Features
- If a feature changes, the downstream models change too.
- Often a feature is the output of another model.
- Ideally each feature should be treated this way and managed accordingly.
Auxiliary data
- Models can be highly dependent on auxiliary data, such as the options for categorical variables.
- If this data gets out of sync with the model files or code, it can cause code to fail.
Trained model objects
Workflows
- Something needs to remember how the steps were stringed together.
- Use tools like Make files, Airlflow, Luigi and version them.
Version them all together
- Commit hashes
- Manually cultivated version list
- Dates
Reproducibility testing
Traditional software testing is not enough
Model testing
train_model:
command: python run.py train_model --config=config/example-training-config.yml --csv=test/test/boston_house_prices_processed.csv
true_dir: test/true/
test_dir: test/test/
files_to_compare:
- example-boston-train-features.csv
- example-boston-train-targets.csv
- example-boston-test-features.csv
- example-boston-test-targets.csv
- example-boston-validate-features.csv
- example-boston-validate-targets.csv
- example-boston-fitted-params.ymlgenerate_features:
command: python run.py generate_features --config=config/example-training-config.yml
true_dir: test/true/
test_dir: test/test/
files_to_compare:
- boston_house_prices_processed.csv
train_model:
command: python run.py train_model --config=config/example-training-config.yml --csv=test/test/boston_house_prices_processed.csv
true_dir: test/true/
test_dir: test/test/
files_to_compare:
- example-boston-train-features.csv
- example-boston-train-targets.csv
- example-boston-test-features.csv
- example-boston-test-targets.csv
- example-boston-validate-features.csv
- example-boston-validate-targets.csv
- example-boston-fitted-params.yml
score_model:
command: python run.py score_model --csv=test/test/example-boston-validate.csv --config=config/example-training-config.yml
true_dir: test/true/
test_dir: test/test/
files_to_compare:
- example_boston_scores.csvEnvironment management
requirements.txt
conda
Code alignment
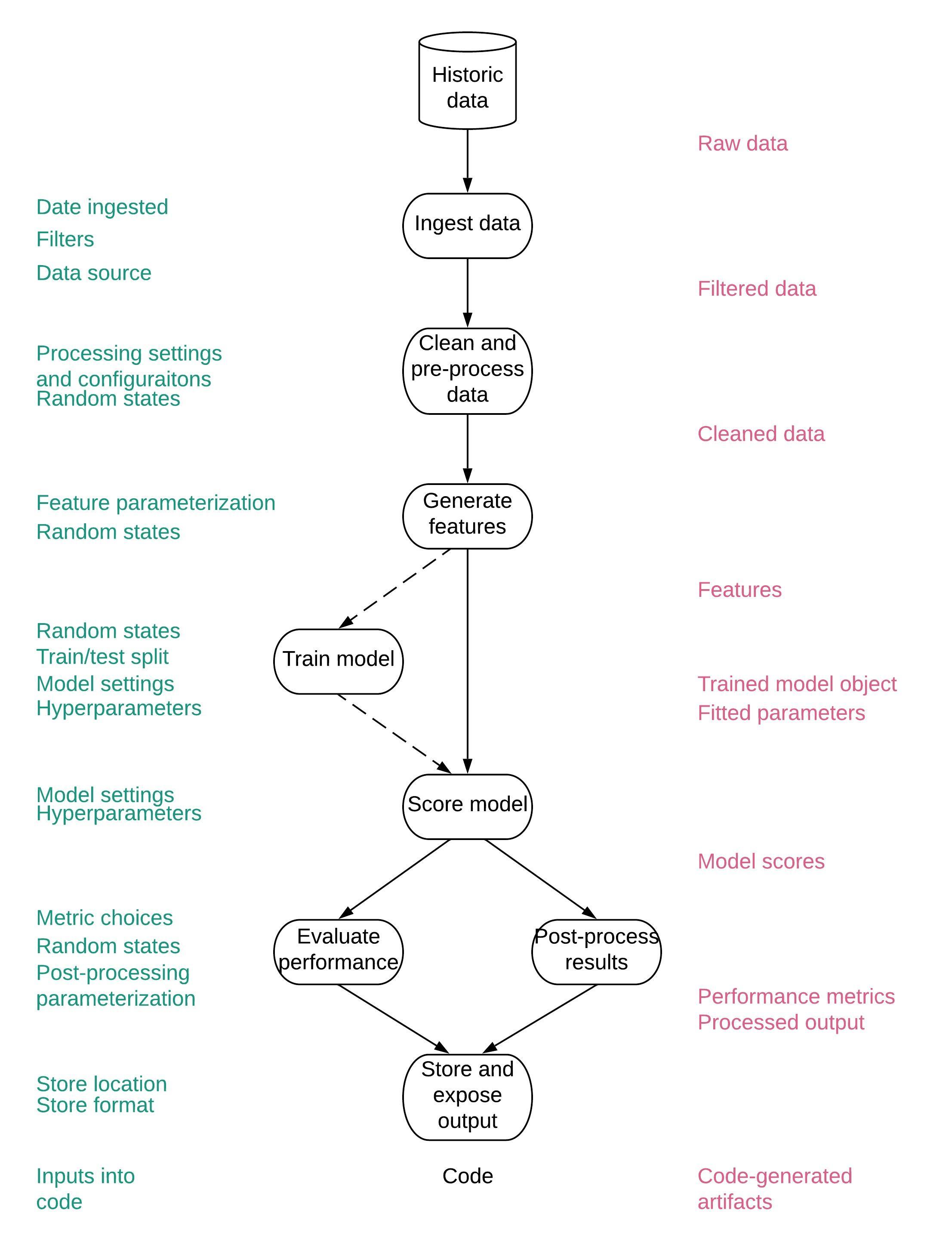
Thank you!
Thank you!
You can find these slides at https://cmawer.github.io/reproducible-model
and the reproducible model template repo at https://github.com/cmawer/reproducible-model
Chloe Mawer | Lineage Logistics
cmawer@lineagelogistics.com | @chloemawer